|
2.2 非阻塞I/O
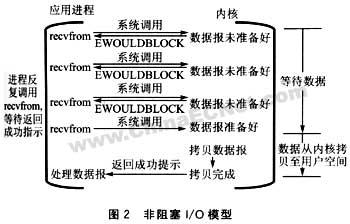
图2中,在非阻塞I/O模型下,I/O操作是即时完成的。当进程调用read函数时,设置了O_NONBLOCK标志,那么即使串口没有数据可读, read函数也会立即返回。此时其返回值为-EAGAIN,表明串口数据未就绪。如果串口有数据可读,则read函数会读取该数据,并返回所读数据的长度。通常轮询I/O的方法就是采用这种模型来读取串口数据的,此时进程必须通过反复调用来检测是否有数据可读。如果轮询频率过低,则容易丢失数据;轮询频率过高,则占用太多处理器的处理周期。
2.3 I/O复用
上述两种I/O模型,是最常用的两种操作I/O的方式;但在面向较复杂、需要处理多个I/O的系统时,这两种模型存在着不足之处。例如:在应用进程中需要对多个I/O设备进行监听,当某个设备可读或可写时,进程能马上得知,并进行相关处理。这时若采用阻塞方式操作I/O,则进程会阻塞在某个设备的I/O 读写操作上而不能适用于这种情况;若采用非阻塞方式,则往往需要定时或循环地探测所有设备,才作相应处理,这种作法相当耗费系统中央处理器的执行周期。可见,上述的两个I/O模型都不能满足这类应用,故此需要引入一种特别的I/O处理机制,即I/O复用。
所谓I/O复用,是指当一个或多个I/O条件(可读、能写或出现异常)满足时,进程能立即知道,从而正确并高效地对它们进行处理。
在uClinux下,系统提供select函数和poll函数,用来支持I/O复用的实现。如图3所示,若使用select的系统调用来查询是否有数据可读时,进程是在等待多个I/O描述接口的任一个变为可读,但此期间并不阻塞进程。当有数据报已准备好时,返回可读条件,并通知进程再次进行系统调用准备读取相应的I/O数据。此时内核就开始拷贝准备好的数据至用户空间,并返回指示进程处理数据报。
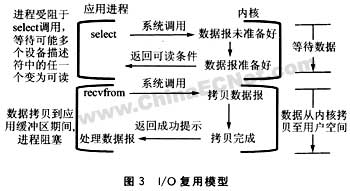
与上面提及的两种I/O模型不同的是:在这个处理过程中,使用了两次系统调用来达到读取数据的目的。虽然两次系统调用的开销似乎更大,但它的最大好处在于能同时等待多个描述符准备好。因此select调用功能更多地是借助了内核来监听I/O设备描述符的。
下面具体介绍select函数的功能及应用。
3 uClinux中基于select的I/O复用机制和工作原理
在系统存在多个输入或输出流但不希望其中任一个流被阻塞的场合,经常使用复用I/O的方法解决。uClinux中,用户程序多使用select机制实现I/O复用控制,select函数允许进程对一个或多个设备文件进行非阻塞的读或写操作。
select的函数定义于中,原型如下:
int select(int n,fd_set*readfds,fd_set*writefds,fd_set*exceptfds,struct timeval*timeout);
该函数允许进程指示内核等待多个事件中的任一个发生,并仅在一个或多个事件发生或经过某指定的时间后才唤醒进程。该函数的第1个参数n表示文件描述符集合中最大值再加1;第2个参数readfds,表示可读的文件描述符集合,用于查看是否有可读取数据;第3个参数writefds表示可写的文件描述符集合,用于查看是否能写入数据;第4个参数exceptfds用于异常控制;最后一个参数timeout决定了select将会阻塞多久才把控制权移交给调用它的进程。调用select之前,必须对此参数进行初始化。若timeout值为O,则select直接返回O。此时I/O操作没有等待就立即返回,相当于一种非阻塞I/O的调用。
共4页: 上一页 [1] 2 [3] [4] 下一页
|